

Microsoft Fabric: How Did We Get Here?
We’ve been discussing Microsoft Fabric quite a bit in this space lately. As excitement around Fabric continues to grow, we’ve fielded many questions from customers about what Fabric actually is (and isn’t). Some of the more notable questions we’ve received along these lines includes the following:
- Isn’t Fabric just the next evolution of legacy data warehouse solutions like Azure SQL Data Warehouse and Azure Synapse Analytics?
- How does Fabric relate to other Microsoft data products such as Power BI, Azure SQL, Synapse, and Azure Data Lake?
- Is Fabric a data warehouse or a data lake?
- Also, what’s all this talk about “data lakehouses”?
- How does OneLake fit into all this?
- What other buzzwords did Microsoft cram into this Fabric story? 😆
This blog post will attempt to answer these questions and illustrate how all these concepts come together to reimagine what a comprehensive data platform looks like in the modern enterprise. If you find yourself tripping over all these new buzzwords, this is the blog for you.
Data Architectures: A Brief History of Time
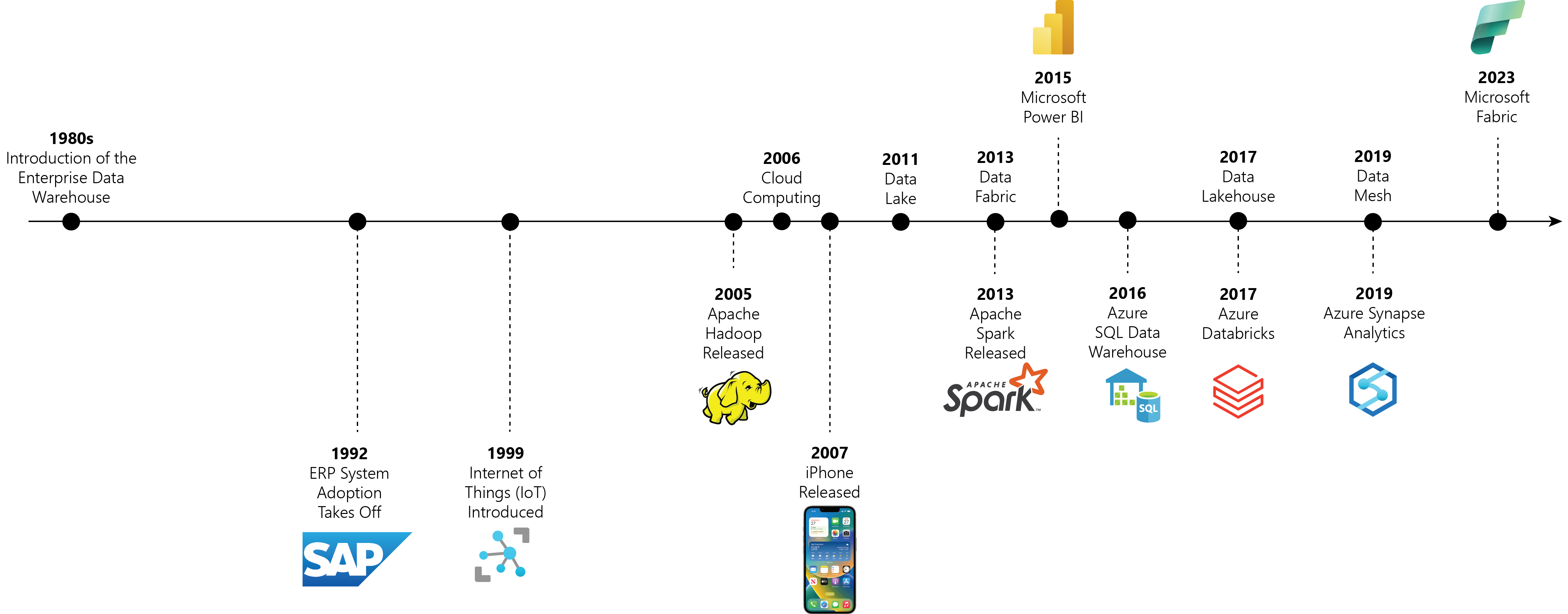
To understand how Fabric came together, it’s helpful to take a look at the evolution of data architectures over the course of the past 40 years or so. We’ll keep the history lesson brief but find that it’s very useful to illustrate the why behind all these new architectures. As we progress through our journey across time, we’ll use the timeline depicted in Figure 1 as our reference.

Figure 1: Evolution of Data Architectures Timeline
Data Warehouse Origins: Moving from OLTP to OLAP
In the early days of enterprise computing (circa the 1960s and 1970s) data strategies were haphazard at best. During those days, most business reports were being driven directly from the online transaction processing (OLTP) systems where the data was being generated — mainframes, early ERP systems, specialty business systems, and so forth. However, as these systems continued to grow and the volume of data being produced by these systems skyrocketed, it became clear that the needs of reporting systems differed from those of operational systems.
In the 1980s, a new architectural model emerged — the so-called “data warehouse”. With the data warehouse architecture, customers began replicating data from their OLTP systems into standalone databases that were optimized for business intelligence (BI) and reporting requirements. While some data warehouses were built on top of popular relational database management systems (RDBMS) like Oracle or IBM DB2, other data warehouse products emerged that were optimized for larger volumes of data and multi-dimensional analysis (e.g., cubes and MDX).
Regardless of the specific physical architecture, the point of the data warehouse was to introduce a separate and standalone system that’s optimized for online analytical processing (OLAP). As you can see in Figure 2 below, this data warehouse can be used to drive complex reporting and data visualization requirements without disrupting the origin OLTP system(s).

Figure 2: Data Warehouse Concept
Big Data and the Cloud
Although steep competition in the data warehouse market introduced many new products/techniques, the basic concepts around data warehouses did not change very much for the better part of 20 years. Indeed, apart from the strategic introduction of data marts for organizational/logistical purposes, it’s been pretty much business as usual for many organizations since the late 1990s/early 2000s.

Figure 3: Data Warehouse vs. Data Marts — MarsJson, CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
However, in the mid-2000s, there were several technology innovations that began to disrupt the status quo:
- In 2005, the term “big data” was coined to address the terabytes of unstructured and semi-structured data that was starting to pile up outside of enterprise data warehouses.
- In 2006, Amazon launched their Amazon Web Services (AWS) cloud platform, ushering in the age of cloud computing. Other major players like Microsoft and Google jumped on this bandwagon shortly thereafter.
- In 2007, Apple introduced the world to the iPhone. Although seemingly unrelated, this milestone marked the beginning of an exponential growth curve in terms of the amount of data being produced worldwide year over year. Combined with the proliferation of data coming in via the Internet of Things (IoT), customers suddenly had to deal with the fact that large volumes of useful data were being produced from unstructured data sources.
Collectively, these milestones gave rise to several new architectural paradigms focused on managing large volumes of unstructured data. As you can see in Figure 1 above, a couple of notable additions here included the introduction of Hadoop and Apache Spark. These frameworks enabled made it possible for companies to build data warehouse-like solutions on top of their unstructured data.
One of the more powerful concepts introduced by frameworks like Hadoop and Spark is the idea of a distributed file system built on top of low-cost storage solutions that can be scaled horizontally (see Figure 3 below). This flexible design approach intersected perfectly with emerging low-cost cloud storage services like AWS S3 and Azure Blob Storage.

Figure 4: Hadoop Distributed File System (HDFS) Concept
Data Lakes
By 2011, the convergence of big data frameworks and flexible storage appliances gave rise to data lakes. In a nutshell, a data lake is a centralized repository that stores large volumes of raw data in its native format until needed for analysis.
In its simplest form, a data lake can be created on top of some kind of flexible storage system. For example, it’s very easy (not to mention cheap) to create your own home-grown data lake on top of Azure Data Lake Storage. From here, you can use frameworks like Apache Spark to analyze the lake data and put it to work for big data or data science-related activities.
As the data lake concept grew in popularity, a new segment of hybrid cloud-based data products entered the market, presenting customers with options to begin integrating unstructured data from data lakes with structured data stored within their data warehouse. However, in the early days, the results were pretty mixed as these two approaches were generally at odds with one another. As a result, data silos began popping up all over the place.
From Data Swamps to Data Lakehouses
While customers struggled to figure out what to do with the data hosted in their data lakes, it became more and more common for well-intentioned data lakes to turn into data swamps. In the best case, these data swamps collected semi-structured and unstructured data from disparate sources into a somewhat organized repository where files go to die.
In an effort to bring order out of chaos, industry architects introduced three new architectural concepts into the mix. Though each concept stands on its own, the three concepts are quite complementary to one another and brought some much-needed structure to data lake management:
- Data Fabric: Data fabric is an architecture that uses extensive metadata to enable consistent data management, integration, and orchestration across hybrid multi-cloud environments. We delved pretty deep into this concept in my previous blog post.
- Data Lakehouse: As the name suggests, a data lakehouse is a unified data platform that combines the storage capabilities of a data lake with the data management features of a data warehouse. For example, while a data lake might contain an assortment of CSV files, a data lakehouse organizes those files into a folder structure that contains some kind of metadata that describes the shape of those files such that they can be used like tables from a data warehouse. It’s very much a best-of-both-worlds proposition.
- Data Mesh: A data mesh is a decentralized data architecture that treats data as a product and assigns ownership to domain-specific teams. From a logistical standpoint, the data mesh makes it easier for multi-disciplinary teams from individual business units to come together to mine for insights from their own structured and unstructured data sources.
Building the Microsoft Intelligent Data Platform
During the time that the industry was figuring out what to do with all the data accumulating in data lakes (circa 2011–2019), Microsoft was hard at work trying to establish itself as a leader in the data and analytics space. Although Microsoft had always been a player with its SQL Server platform, they really put the world on notice with the release of Power BI back in 2015. This product release was a massive success and Power BI shot to the top of just about every BI chart in existence almost overnight.
In parallel, Microsoft released several new data products as part of their new Microsoft Intelligent Data Platform:
- Azure SQL Data Warehouse: This was Microsoft’s first attempt at offering a managed data warehouse solution on top of its Azure SQL cloud service (think cloud-managed SQL Server). With mass parallelization capabilities, Azure SQL Data Warehouse offered some powerful features, but it was still mostly a traditional data warehouse architecture.
- Azure Synapse Analytics: This solution replaced Azure SQL Data Warehouse. Besides completely overhauling the core architecture and scaling capabilities, Microsoft also designed Synapse from the ground up to clearly separate data from the compute resources used to access it. This separation of concerns made it possible for Synapse to support data virtualization. With support for PolyBase, Synapse enabled developers to query data from both SQL tables and external unstructured data sources like CSV files.
- Azure Databricks: According to Microsoft, Databricks is a “fully managed first-party service that enables an open data lakehouse in Azure”.
These products, combined with Azure services like Azure Data Lake and Azure Machine Learning, provided customers with a powerful array of services they could mix-and-match to build their data platform.
It All Comes Together with Fabric
As Microsoft learned from its customers and the industry as a whole converged on common best practices and architectural patterns, the blueprint for what we now know as Fabric really started to crystalize. Although Microsoft definitely renovated and expanded the capabilities of many of its core services, you can think of Fabric as a SaaS solution that provides customers with pre-built and optimized data platform.
To put all this into perspective, let’s briefly review some of the core concepts behind Fabric’s design:
- Each Fabric tenant has one (and only one) data lake — OneLake.
- OneLake storage can be partitioned into domains and workspaces, supporting the kind of decentralized management prescribed with the data mesh architecture.
- Like Azure Synapse Analytics, Fabric calls for a strict separation between data stored in OneLake and the compute resources that are used to access it. This separation allows Fabric to be used as a data warehouse, a data lake, or a data lakehouse. It’s up to the customer which architecture(s) they want to implement and there are no cost/performance penalties associated with choosing one approach over another.
- Consumers can use a wide variety of protocols/tools to access data in OneLake: SQL, Spark, notebooks, and so forth.
- As the name suggests, Microsoft Fabric embodies many of the core principles associated with the data fabric architecture. So, it can be used both as a data fabric and a data mesh.
Closing Thoughts
Microsoft Fabric is a SaaS-based data platform that meets customers where they are. Although you could certainly build your own data platform from scratch using a wide variety of open-source libraries and cloud services, Fabric is intended the take the guesswork out of the process.
In this writer’s humble opinion, Fabric is truly an engineering marvel — carefully weaving together roughly 20 years’ worth of data architecture evolution into a seamless platform that supports a wide variety of modern use cases for data processing.
Of course, you don’t have to understand all this context to put Fabric to work for your business. However, I hope that this little trip down memory lane has helped you to more clearly see the Fabric value proposition. As always, if you have questions, please feel free to reach out as we love to talk about this stuff.